企业级RAG落地指南
RAG实战落地高精度指南

别再被R-A-G教程骗了:一位一线工程师的企业级落地血泪史
如果你觉得看了几篇教程,跑通一个开源项目,就能搞定企业的RAG(检索增强生成)系统,那我劝你趁早放弃幻想。过去一年多,我为多种(金融,制药等)企业搭建知识库,为他们处理堆积如山的内部文档,才发现真实世界的RAG,90%的工作都是在填教程里没提过的坑。
这篇文章不谈基础,只讲那些能决定项目成败,却又总被忽视的“残酷真相”。
真相一:一切始于“垃圾分类”,而不是“向量召回”
所有教程都有个美好的前提:你的数据是干净的。但企业现实呢?我面对的文档库里,有上世纪90年代用打字机写完再扫描的、字迹模糊的研究报告,旁边躺着一份500页、格式精美的现代财报。
如果你用同样的流程处理它们,等待你的只有无尽的“我不知道”或者“根据文档,信息不存在”。我曾因此浪费数周时间调试模型,最后才醒悟:在谈论任何高级算法之前,必须先对文档进行“质量定级” 。
我后来建立了一套雷打不动的准则:
- A类文档(高质量) :文本清晰,结构规整。启用最精细的层次化解析,完整保留章节、段落、图表关系。
- B类文档(中等质量) :有少量OCR错误或格式混乱。走标准处理流程,但必须加上额外的清洗和修复脚本。
- C类文档(低质量) :扫描件、手写体。直接放弃复杂解析,采用固定大小分块,并打上“低信度”标签,提示用户结果可能不准。
这个看似原始的“文档分诊台”,比更换任何SOTA嵌入模型,解决的无效召回问题都要多。记住,垃圾进,垃圾出,AI也救不了。

真相二:元数据,才是那个回报率最高的“杠杆”
新手痴迷于向量和模型,而老手敬畏于元数据。我敢说,我40%的有效工作时间,都投入到了设计和提取元数据上,它的投资回报率高得惊人。

为什么?因为企业的提问充满了“隐性上下文”。
- 当一个制药研发人员问“CAR-T疗法的副作用”,他隐含的筛选条件是: [文档类型:临床试验报告] + [治疗领域:肿瘤学] + [监管机构:FDA批准] 。
- 当一个金融分析师问“A公司去年的营收”,他需要的是: [公司:A] + [财报周期:2023财年] + [指标:营收] 。
没有元数据,你的RAG系统就是个眼神不好的图书馆员,只能在茫茫书海里乱翻。我们为每个核心领域都构建了专用的元数据模式,并且坚决不用LLM做提取(它在结构化信息提取上既不稳定又昂贵),而是用最可靠的正则表达式和关键词列表。这活儿很枯燥,很“不性感”,但它能让你的系统在回答问题前,就过滤掉90%的噪音。
真相三:纯语义搜索是个“美丽的谎言”
“语义相似”这个词听起来很智能,但在专业领域,它常常失灵。我统计过,在处理金融和法律文档时,纯语义搜索的失败率高达15%-20% 。
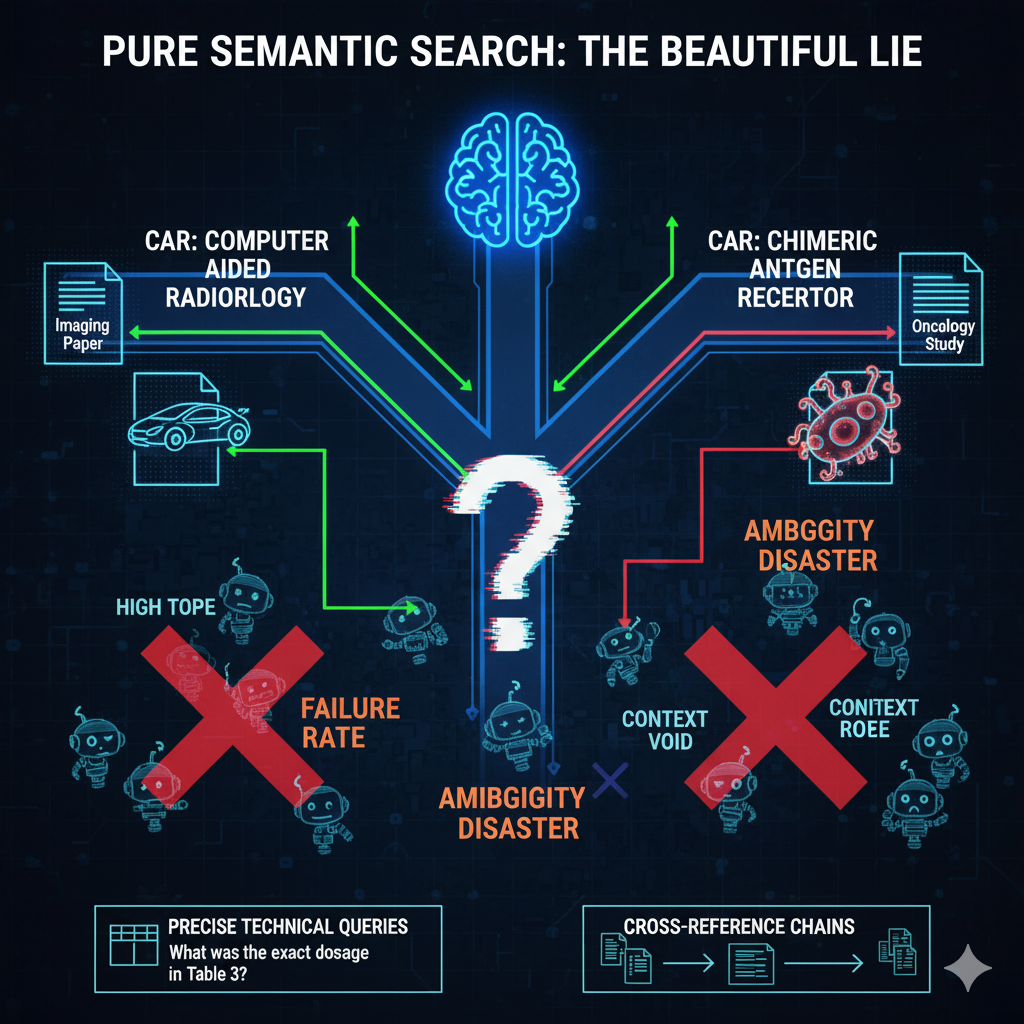
最典型的两大翻车现场:
- 缩写词灾难:“CAR”在肿瘤学里是“嵌合抗原受体”,但在汽车行业报告里是“汽车”。向量空间里,它们可能离得很近,但在业务上,谬以千里。
- 精确数据查询失效:用户问“第三季度运营成本是多少?”,语义搜索可能会给你返回一段“关于运营成本分析”的宏观论述,而不是那个表格里最关键的数字。
解决方案?必须是混合动力。
- 语义搜索保下限:负责处理开放式、探索性的问题。
- 关键词和规则保上限:利用BM25这类经典算法和精确匹配,处理专业术语、产品代号、法规编号这类查询。
- 知识图谱做扩展:在预处理时,解析出文档间的引用关系。当用户找到一份关键报告后,系统能主动提示“引用了这份报告的另外5份文件或许也值得一看”。
真相四:表格,被遗忘的金矿与噩梦
如果你的RAG系统会忽略表格,那你可能错过了文档里一半的价值。企业的核心数据——财务报表、实验结果、合规清单——几乎全在表格里。
标准RAG流程处理表格约等于灾难,它要么无视,要么把结构化数据拉平成一段无意义的长文本。我们必须为表格开“小灶”:
- 独立处理流水线:将表格从文档中“抠”出来,单独处理。
- 双重嵌入:既对表格的结构化数据(转为CSV或JSON)进行嵌入,也对表格的标题、摘要做一个语义描述的嵌入。
- 与元数据联动:查询时,如果系统识别到用户在问具体数值,会优先在“表格库”中进行检索。
这很麻烦,但绝对值得。能准确回答“对比A、B产品在二期临床试验中的疗效数据”的RAG,才算真正产生了价值。
真相五:比起模型参数,客户更关心成本和稳定
在企业里,没人关心你的模型有多少个参数,他们只关心三件事:成本、数据安全、系统会不会崩。
这直接决定了技术选型:
- 拥抱开源:像Qwen、Llama这类经过微调的开源大模型,不仅能让你把数据牢牢控制在本地,避免了数据隐私风险,其部署和推理成本也远低于GPT-4o这类API。在高并发场景下,成本能相差一个数量级。
- 硬件投入是必须的:别指望用消费级显卡撑起一个企业级应用。我们会直接告诉客户,项目需要至少几块A100级别的GPU。这是一笔前期投入,但能换来后续的稳定性和扩展性。
- 工程稳定性大于一切:一个偶尔惊艳但频繁超时的系统,价值为零。我们花在请求队列管理、资源调度、模型量化和并发控制上的精力,远超算法调优。
结语
总而言之,企业级RAG的落地,是一场从算法为中心到工程为王的转变。它考验的不是你对最新论文的了解程度,而是你对数据、业务和基础设施的掌控能力。别再沉迷于那些光鲜亮丽的Demo,卷起袖子,去解决那些真正棘手的“脏活累活”,这才是价值所在。